Linux Server Monitoring mit Netdata
September 7, 2020 - Lesezeit: 8 Minuten
Über die Jahre habe ich die meisten meiner Linux Server per Hand und bei Bedarf überwacht. Viele der nützlichen Tools wie (h)top, netstat, vnstat oder auch das gerne von mir genutzte nmon sind nur wenige MB groß und oftmals direkt im Grundsystem der Distributionen oder zumindest immer in den offiziellen Paketquellen enthalten. Dazu werden viele Systeminformationen direkt vom Kernel im /proc Verzeichnis bereitgestellt und können dort abgerufen werden. Gleiches gilt für die Log Dateien in /var/log und die oftmals guten Dienstmeldungen per systemctl status oder auch im journalctl.
Monitoring mit Boardmitteln hilft auch sich auf den eigenen Systemen besser auszukennen und mit kurzen Shell Scripten lassen sich auch Alarme, z.B. per Mail realisieren.
Im schlimmsten Fall ist ein "fancy" Monitoring Tool Teil des Problems, muss auch wieder regelmäßig Updates erhalten und frißt zudem nicht selten zusätzliche Ressourcen von 3-5%. Nicht die Welt, aber immerhin. Wer noch mit "richtiger" Hardware (und sei es nur ein Raspi) arbeitet kann über jedes Prozent weniger Last zufrieden sein, weil Skalierung ja oft nicht mal so eben geht und wer in der Cloud arbeitet weiß das jede zusätzliche Last oder nötige Skalierung bare Münze kosten kann.
Nun kann bei einer wachsenden Zahl von Servern aber auch jeder Admin irgendwann die Übersicht verlieren, nicht jeder Server lässt sich ständig oder bei Bedarf per Hand kontrollieren, vielleicht müssen auch Kollegen ohne Zugriffsrechte auf das CLI mal wichtige Infos abrufen können und effektiver in Bezug auf das eigene Zeitmanagement wäre es auch. Nun gibt es auf dem Markt seit Jahren etablierte, aber oftmals auch etwas angestaubte oder aufgeblähte Tools wie Nagios und Zabbix, viele kommerzielle Produkte und die momentan extrem beliebte Kombination aus Prometheus und Grafana. Letztendlich für mich aber alles ungeeigenet und viel zu aufwändig. Ok die Charts in Grafana sehen hübsch aus, aber der Konfigurationsaufwand und die Einarbeitung in Prometheus kosten mich unnötige Zeit. Vorgefertigte Dashboards von der Community helfen, erfordern aber bei Änderungen und Herstellerupdates in Prometheus auch wieder Änderungen in Grafana. Ein Traum ...
Netdata
Die einfache und vor allem gute Open Source Lösung ist für mich das auf python basierende netdata. Für mich mit folgenden Vorteilen:
- ressourcenschonend, benötigt nie mehr als 1% CPU
- einfache Installation und Konfiguration
- Weboberfläche mit Dashboard, aber nur read-only, was vor allem Sicherheitstechnisch deutlich entspannter ist (Cockpit z.B. ermöglicht auch Systemkommandos per Webschnittstelle)
- Die Daten von mehreren netdata Installationen/Servern lassen sich auf einem Server sammeln
- Notifications über Alarme per Mail, Discord, Slack, Rocket.Chat, Teams usw.
https://github.com/netdata/netdata
Installation
Eine etwas ältere Version ist z.B. auch in den Paketquellen von Ubuntu enthalten. Empfehlen würde ich aber per curl den offiziellen Kickstarter herunterzuladen und zu verwenden. Dieser ist sehr gelungen und lässt einen die bei der Installation durchgeführten Schritte sehr schön mitverfolgen. Bash Shell wird benötigt, falls nicht eh im Einsatz.
cd /tmp
curl https://my-netdata.io/kickstart.sh -o kickstart.sh
chmod +x kickstart.sh
./kickstart.sh --stable-channel --disable-telemetryDie Optionen für den Kickstart kann man auch weglassen, dann erhält man automatisch die nightly Builds und es werden anonyme Statistiken erhoben die den Entwicklern helfen Ihr Tool zu verbessern. Kann aber auch nachträglich noch angepasst werden.
Probleme
In aktuellen Ubuntu und Debian-Server Versionen (20.04 LTS und Debian 11) hatte ich Probleme mit der Installation über den Kickstarter. Die Installation lief zwar erfolgreich durch, allerdings wollte das Webinterface sich einfach nicht öffnen lassen. Nach viel probieren und suchen bin ich endlich dahinter gekommen das sich der Kickstarter wohl geändert hat und nun "nur" noch eine Apt Quelle hinzufügt und das Paket so installiert. Irgendwas muss dabei aber nicht richtig funktionieren. Wie auch immer, wenn man den Kickstarter mit dem Flag build-only ausführt, wird die Installation nicht mehr über apt ausgeführt sondern manuell und es funktioniert wieder. Also entweder direkt:
./kickstart.sh --build-only --stable-channel --disable-telemetry
oder falls die Installation schon erfolgt ist, aber nicht funktioniert:
./kickstart.sh --build-only --reinstall
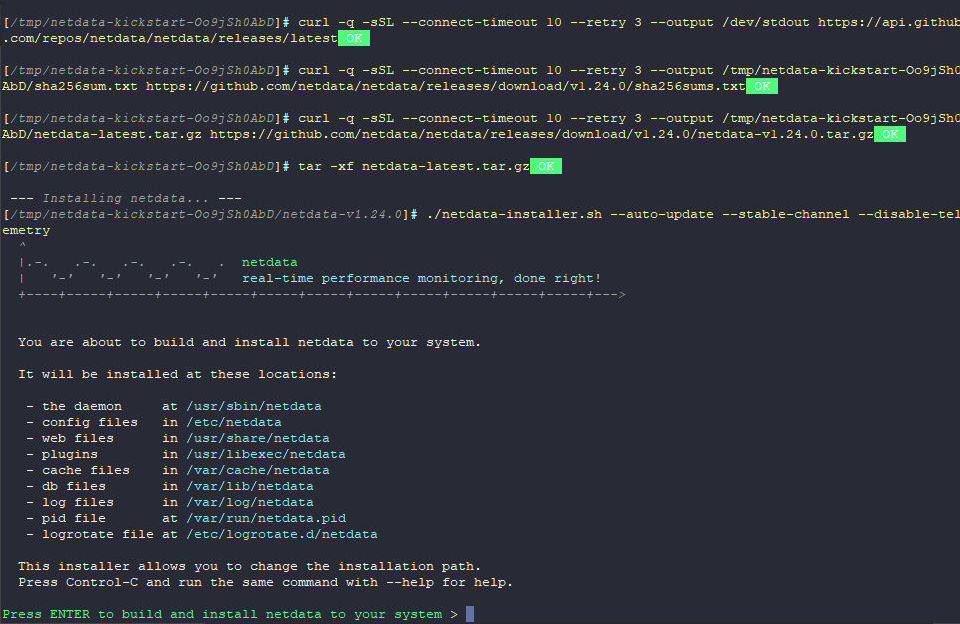
Nach ein paar Minuten ist der Installer dann auch durch und im Prinzip ist man direkt startklar. Zum Abschluss gibt es noch die nötigsten Infos.
start | stop | status per systemctl
Die Weboberfläche erreicht man über
http://serverip:19999
Wenn das Netzwerk des Servers von außen erreichbar ist kann man das Dashboard zusätzlich absichern, dazu gibt es alle Infos hier:
https://learn.netdata.cloud/docs/agent/running-behind-nginx
Denkbar wäre auch eine Firewall Regel. Wer mit ufw arbeitet könnten z.B. folgende Regel ergänzen:
(sudo) ufw allow from EineIP to any port 19999
Konfiguration der Mail Benachrichtigung
Dafür muss der Server natürlich in der Lage sein Mails zu versenden, z.B. per Sendmail, Postfix etc. Funktioniert das bereits oder wird die interne Mailbox des root Users eh weitergeleitet, dann braucht man eigentlich gar nichts einstellen. Ansonsten die entsprechende Konfiguration aufrufen unter:
cd /etc/netdata/
sudo ./edit-config health_alarm_notify.confDort nach dem Wert:
DEFAULT_RECIPIENT_EMAIL
schauen und eine Mailadresse einsetzen. Ich habe zusätzlich noch
EMAIL_CHARSET="UTF-8"
einkommentiert. Das war es dann auch schon. Man kann den Alarm auch testen:
sudo su -s /bin/bash netdata
/usr/libexec/netdata/plugins.d/alarm-notify.sh testMehr Infos und Optionen zu Notifications sind in der offiziellen Doku beschrieben:
https://learn.netdata.cloud/docs/agent/health/notifications
Ich habe z.B. noch für das von meinem Team verwendete Rocket.Chat einen WebHook angelegt und bekomme so mögliche Alerts per Mail und Chat. Dafür zuerst einen Webhook anlegen, wie das geht steht hier:
https://docs.rocket.chat/guides/administrator-guides/integrations
Dann die Netdata Config wie oben beschrieben aufrufen und diese Einstellungen anpassen:
SEND_ROCKETCHAT="YES"
ROCKETCHAT_WEBHOOK_URL="Webhook URL"
DEFAULT_RECIPIENT_ROCKETCHAT="@Username oder auch ein #Channel"
Mehrere Netdata Instanzen (Nodes) verwalten
Coming soon