MySQL Server 8 Upgrade Fehler & Hinweise
August 10, 2022 - Lesezeit: 4 Minuten
Mit dem MySQL Server 8, welcher ab Ubuntu 20 LTS Standard ist und auch bei einem System Upgrade installiert wird, wurden einige Server-Variablen entfernt und hinzugefügt.
https://dev.mysql.com/doc/refman/8.0/en/added-deprecated-removed.html
Das kann bei einem Upgrade zu Fehlern führen, sofern man die entfernten Variablen verwendet hat und ggf. lässt sich der Server nicht mehr starten.
In meinem Fall war dies nach einem Upgrade von Ubuntu 18.04 LTS auf Ubuntu 20.04 LTS der Fall.
Die Logdatei unter /var/log/mysql/error.log gab den folgenden Fehler aus:
[Server] unknown variable 'query_cache_limit=1M'.Also die Variable in /etc/mysql/my.cnf auskommentiert und direkt den nächsten Fehler wegen einer entfernten Variable bekommen:
[Server] unknown variable 'query_cache_size=16M'.Diese ebenfalls auskommentiert und der MySQL Server ließ sich wieder starten.
Hintergrund: Die beiden Variablen bezogen sich auf den query cache, welcher eine bliebte Methode zum MySQL-Server Performance Tuning war. Seit MySQL 5.7.20 galt dieser aber als veraltet und wurde mit MySQL 8.0 dann komplett entfernt sowie dann auch die Variablen. Wer auf den query cache nicht verzichten kann, findet unter https://proxysql.com/ eine Möglichkeit oder kann diesen auch noch unter MariaDB verwenden. Generell gilt die Entfernung wohl jedoch eher dem Aufruf besseren Code zu schreiben. Ein guter Artikel zu dem Thema findet sich auch hier: https://mysqlquicksand.wordpress.com/2020/05/08/10-reasons-why-mysql-query-cache-should-be-switched-off/
Ein weiteres Problem hatte ich dann mit einem Script, welches einen MSSQL Export als CSV Datei durchführt und diese wieder nach MySQL importiert (siehe auch https://www.le-brice.de/mssql-export-unter-ubuntu-linux). Dazu verwende ich einen MySQL Befehl der auf LOAD DATA LOCAL INFILE zurückgreift:
LOAD DATA LOCAL INFILE 'import.csv' INTO TABLE tablename FIELDS TERMINATED BY ';' LINES TERMINATED BY '\n'Bei der Verwendung des LOAD DATA LOCAL Statement gibt es seitens der MySQL Entwickler Sicherheitsbedenken, weshalb dieses in MySQL 8 nicht mehr standardmäßig verwendet werden kann. Siehe:
https://dev.mysql.com/doc/refman/8.0/en/load-data-local-security.html
Um das Statement wieder verwenden zu können muss sowohl der MySQL-Server, als auch der verwendete MySQL-Client (in meinem Fall der Standard CLI-Client auf den das Script zurückgreift) die local_infile Variable auf 1 gesetzt haben. Dies kann in der my.cnf unter /etc/mysql/my.cnf geschehen.
Der [mysql] Bereich wird sehr wahrscheinlich bereits vorhanden sein, der [client] Bereich ggf. noch nicht und kann am Ende der Konfiguration hinzugefügt werden. Kommentare zur Erinnerung sind empfohlen.
[mysql]
#allow LOAD DATA LOCAL statement on server side
local_infile = 1
#allow LOAD DATA LOCAL statement on client side
[client]
local_infile = 1 Danach den MySQL Server neustarten und das LOAD DATA LOCAL INFILE Statement kann wieder verwendet werden.
Übrigens kann man auch die Variable per SQL-Client prüfen:
mysql> show global variables LIKE '%INFILE%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| local_infile | ON |
+---------------+-------+
1 row in set (0,00 sec)
mysql>Da es sich hier, abhängig von der Serververwendung und Umgebung, um eine durchaus zu beachtene Sicherheitswarnung handelt empfehle ich den Abschnitt aus der oben genannten Referenz "Restricting Files Permitted for Local Data Loading" zu beherzigen oder ggf. auch das Script umzubauen um nicht mehr auf die Funktion zurückgreifen zu müssen.
Linux Boot Partition vergrößern ohne LVM
August 8, 2022 - Lesezeit: 5 Minuten
Das die Boot Partition auf einem Linux Server vollläuft ist ein Problem das mir immer mal wieder über den Weg läuft. Man sollte meinen in Zeiten von LVM, Containern, Cloud etc. wäre das nicht mehr der Fall, aber bei Servern die schon sehr lange in Betrieb (aber trotzdem durch Upgrades aktuell sind, weil Linux das halt gut kann) sind kann es trotzdem immer wieder vorkommen. Auf jeden Fall bekommt man dann bei der Installation von Updates und neuen Kernel Images immer wieder Probleme. Meistens reicht es vorerst aus alte Kernel Images von der Boot Partition zu löschen (Achtung vorher mit uname -a immer prüfen welches Image der Server grad verwendet), aber auf Dauer ist das einfach lästig.
Also muss die Boot Partition vergrößert werden. Hat man ein LVM, kein Problem. Teilweise sind die LVM Installationen aber auch früher so gemacht worden, dass genau die Boot Partition nicht im LVM ist. Dann hat man mehr oder weniger ein Problem und bei den Szenarien ohne LVM auch. Jetzt kann man mit und ohne Live-System am Partitionslayout schrauben und sich irgendwie etwas zurechtfummeln. Das kann funktionieren, ist aber je nach Zeit und Kenntnisstand umständlich und auch fehleranfällig, dann kann man gleich den Server sauber neu aufsetzen. Will und kann man das nicht, ist aus meiner Erfahrung die einfachste Möglichkeit die Boot Partition auf eine neue Festplatte zu verschieben und dann zu vergrößern. Das hat bis jetzt immer funktioniert. Warum auf eine neue Platte? Weil keine bestehenden Partitionen auf der neuen Platte vorhanden sind und die Boot Partition dann nach hinten problemlos vergrößert werden kann.
Hinweis: Root/Sudo wird benötigt. Außerdem ist ein Backup natürlich dringend empfohlen, da Änderungen an den Festplatten immer ein Risiko mitbringen, dafür ist jeder selbst verantwortlich.
- Eine neue Festplatte einhängen falls eine Virtualisierung besteht oder einbauen, 1 GB reichen bereits, wer überzeugt ist das der Server auch in 10 Jahren noch so läuft macht auch einfach 2 GB und hat vermutlich seine Ruhe
- Damit die neue Festplatte erkannt wird muss der Server ggf. neugestartet werden oder folgendes Kommando ausgeführt werden, welches die verbundenen Devices neu einliest:
echo "- - -" | sudo tee /sys/class/scsi_host/host*/scan - Prüfen mit z.B.
lsblkob die neue Festplatte nun erscheint und unter welcher Bezeichnung, in meinem Fall ist es/dev/sdb
WICHTIG Wenn es bei euch nicht /dev/sdb ist, im folgenden /dev/sdb immer entspechend ersetzen, sonst werden ggf. andere Partitionen oder Festplatten in eurem System verändert oder gelöscht.
- Mit
fdisk /dev/sdbeine neue Partition erstellen (geht natürlich auch mit parted, falls man damit lieber arbeitet)
Befehl (m für Hilfe): n
Partitionstyp
p Primär (0 primär, 0 erweitert, 4 frei)
e Erweitert (Container für logische Partitionen)
Wählen (Vorgabe p): p
Partitionsnummer (1-4, Vorgabe 1): 1
Erster Sektor (2048-4194303, Vorgabe 2048):
Letzter Sektor, +Sektoren oder +Größe{K,M,G,T,P} (2048-4194303, Vorgabe 4194303): +1G
Eine neue Partition 1 des Typs „Linux“ und der Größe 1 GiB wurde erstellt.
Befehl (m für Hilfe): w
Die Partitionstabelle wurde verändert.
ioctl() wird aufgerufen, um die Partitionstabelle neu einzulesen.
Festplatten werden synchronisiert- Zur Sicherheit dem Kernel die Änderungen an der Partitionstabelle nochmal mitteilen:
partprobe - Nun die Daten 1:1 von der alten Boot Partition auf die neue kopieren. Hier sollte NICHT mit cp gearbeitet werden sondern mit
dd, welches bitgenau kopiert und somit auch das Dateisystem mitkopiert. dd arbeitet ohne Rückfragen, also den Befehl vorher gut checken:dd if=/dev/sda1 of=/dev/sdb1 bs=512 conv=noerror,sync - Die neue Partition auf Fehler prüfen:
e2fsck /dev/sdb1 /dev/sdb1: sauber, 315/124496 Dateien, 157347/248832 Blöcke resize2fs /dev/sdb1um die Partition auf die zuvor angelegten 1GB zu vergrößernresize2fs 1.44.1 (24-Mar-2018) Dateisystem bei /dev/sdb1 ist auf /boot eingehängt; Online-Größenänderung ist erforderlich old_desc_blocks = 1, new_desc_blocks = 4 Das Dateisystem auf /dev/sdb1 is nun 1048576 (1k) Blöcke lang./etc/fstabbearbeiten und die neue Boot Partition eintragen bzw. den alten Eintrag bearbeiten. Perblkidkann ggf. die UUID der neuen Boot Partition abgefragt werden und auch der Dateisystemtyp. Den bekommt man übrigens auch mitlsblk -foderdf -Th.
...
# <file system> <mount point> <type> <options> <dump> <pass>
UUID=b214661e-58ef-4dc8-8d76-ea254ece99aa /boot ext4 defaults 0 2
...- System neustarten und danach mit
df -hoderlsblkprüfen ob alles passt.
Linux Server Monitoring mit Netdata
September 7, 2020 - Lesezeit: 8 Minuten
Über die Jahre habe ich die meisten meiner Linux Server per Hand und bei Bedarf überwacht. Viele der nützlichen Tools wie (h)top, netstat, vnstat oder auch das gerne von mir genutzte nmon sind nur wenige MB groß und oftmals direkt im Grundsystem der Distributionen oder zumindest immer in den offiziellen Paketquellen enthalten. Dazu werden viele Systeminformationen direkt vom Kernel im /proc Verzeichnis bereitgestellt und können dort abgerufen werden. Gleiches gilt für die Log Dateien in /var/log und die oftmals guten Dienstmeldungen per systemctl status oder auch im journalctl.
Monitoring mit Boardmitteln hilft auch sich auf den eigenen Systemen besser auszukennen und mit kurzen Shell Scripten lassen sich auch Alarme, z.B. per Mail realisieren.
Im schlimmsten Fall ist ein "fancy" Monitoring Tool Teil des Problems, muss auch wieder regelmäßig Updates erhalten und frißt zudem nicht selten zusätzliche Ressourcen von 3-5%. Nicht die Welt, aber immerhin. Wer noch mit "richtiger" Hardware (und sei es nur ein Raspi) arbeitet kann über jedes Prozent weniger Last zufrieden sein, weil Skalierung ja oft nicht mal so eben geht und wer in der Cloud arbeitet weiß das jede zusätzliche Last oder nötige Skalierung bare Münze kosten kann.
Nun kann bei einer wachsenden Zahl von Servern aber auch jeder Admin irgendwann die Übersicht verlieren, nicht jeder Server lässt sich ständig oder bei Bedarf per Hand kontrollieren, vielleicht müssen auch Kollegen ohne Zugriffsrechte auf das CLI mal wichtige Infos abrufen können und effektiver in Bezug auf das eigene Zeitmanagement wäre es auch. Nun gibt es auf dem Markt seit Jahren etablierte, aber oftmals auch etwas angestaubte oder aufgeblähte Tools wie Nagios und Zabbix, viele kommerzielle Produkte und die momentan extrem beliebte Kombination aus Prometheus und Grafana. Letztendlich für mich aber alles ungeeigenet und viel zu aufwändig. Ok die Charts in Grafana sehen hübsch aus, aber der Konfigurationsaufwand und die Einarbeitung in Prometheus kosten mich unnötige Zeit. Vorgefertigte Dashboards von der Community helfen, erfordern aber bei Änderungen und Herstellerupdates in Prometheus auch wieder Änderungen in Grafana. Ein Traum ...
Netdata
Die einfache und vor allem gute Open Source Lösung ist für mich das auf python basierende netdata. Für mich mit folgenden Vorteilen:
- ressourcenschonend, benötigt nie mehr als 1% CPU
- einfache Installation und Konfiguration
- Weboberfläche mit Dashboard, aber nur read-only, was vor allem Sicherheitstechnisch deutlich entspannter ist (Cockpit z.B. ermöglicht auch Systemkommandos per Webschnittstelle)
- Die Daten von mehreren netdata Installationen/Servern lassen sich auf einem Server sammeln
- Notifications über Alarme per Mail, Discord, Slack, Rocket.Chat, Teams usw.
https://github.com/netdata/netdata
Installation
Eine etwas ältere Version ist z.B. auch in den Paketquellen von Ubuntu enthalten. Empfehlen würde ich aber per curl den offiziellen Kickstarter herunterzuladen und zu verwenden. Dieser ist sehr gelungen und lässt einen die bei der Installation durchgeführten Schritte sehr schön mitverfolgen. Bash Shell wird benötigt, falls nicht eh im Einsatz.
cd /tmp
curl https://my-netdata.io/kickstart.sh -o kickstart.sh
chmod +x kickstart.sh
./kickstart.sh --stable-channel --disable-telemetryDie Optionen für den Kickstart kann man auch weglassen, dann erhält man automatisch die nightly Builds und es werden anonyme Statistiken erhoben die den Entwicklern helfen Ihr Tool zu verbessern. Kann aber auch nachträglich noch angepasst werden.
Probleme
In aktuellen Ubuntu und Debian-Server Versionen (20.04 LTS und Debian 11) hatte ich Probleme mit der Installation über den Kickstarter. Die Installation lief zwar erfolgreich durch, allerdings wollte das Webinterface sich einfach nicht öffnen lassen. Nach viel probieren und suchen bin ich endlich dahinter gekommen das sich der Kickstarter wohl geändert hat und nun "nur" noch eine Apt Quelle hinzufügt und das Paket so installiert. Irgendwas muss dabei aber nicht richtig funktionieren. Wie auch immer, wenn man den Kickstarter mit dem Flag build-only ausführt, wird die Installation nicht mehr über apt ausgeführt sondern manuell und es funktioniert wieder. Also entweder direkt:
./kickstart.sh --build-only --stable-channel --disable-telemetry
oder falls die Installation schon erfolgt ist, aber nicht funktioniert:
./kickstart.sh --build-only --reinstall
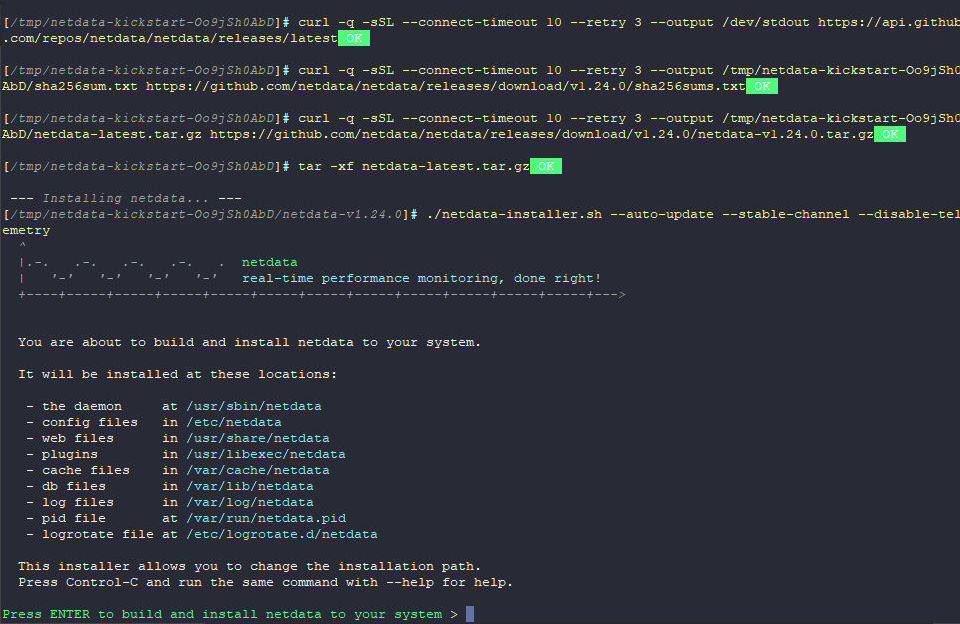
Nach ein paar Minuten ist der Installer dann auch durch und im Prinzip ist man direkt startklar. Zum Abschluss gibt es noch die nötigsten Infos.
start | stop | status per systemctl
Die Weboberfläche erreicht man über
http://serverip:19999
Wenn das Netzwerk des Servers von außen erreichbar ist kann man das Dashboard zusätzlich absichern, dazu gibt es alle Infos hier:
https://learn.netdata.cloud/docs/agent/running-behind-nginx
Denkbar wäre auch eine Firewall Regel. Wer mit ufw arbeitet könnten z.B. folgende Regel ergänzen:
(sudo) ufw allow from EineIP to any port 19999
Konfiguration der Mail Benachrichtigung
Dafür muss der Server natürlich in der Lage sein Mails zu versenden, z.B. per Sendmail, Postfix etc. Funktioniert das bereits oder wird die interne Mailbox des root Users eh weitergeleitet, dann braucht man eigentlich gar nichts einstellen. Ansonsten die entsprechende Konfiguration aufrufen unter:
cd /etc/netdata/
sudo ./edit-config health_alarm_notify.confDort nach dem Wert:
DEFAULT_RECIPIENT_EMAIL
schauen und eine Mailadresse einsetzen. Ich habe zusätzlich noch
EMAIL_CHARSET="UTF-8"
einkommentiert. Das war es dann auch schon. Man kann den Alarm auch testen:
sudo su -s /bin/bash netdata
/usr/libexec/netdata/plugins.d/alarm-notify.sh testMehr Infos und Optionen zu Notifications sind in der offiziellen Doku beschrieben:
https://learn.netdata.cloud/docs/agent/health/notifications
Ich habe z.B. noch für das von meinem Team verwendete Rocket.Chat einen WebHook angelegt und bekomme so mögliche Alerts per Mail und Chat. Dafür zuerst einen Webhook anlegen, wie das geht steht hier:
https://docs.rocket.chat/guides/administrator-guides/integrations
Dann die Netdata Config wie oben beschrieben aufrufen und diese Einstellungen anpassen:
SEND_ROCKETCHAT="YES"
ROCKETCHAT_WEBHOOK_URL="Webhook URL"
DEFAULT_RECIPIENT_ROCKETCHAT="@Username oder auch ein #Channel"
Mehrere Netdata Instanzen (Nodes) verwalten
Coming soon
GoAccess
April 21, 2020 - Lesezeit: ~1 Minute
Da ich auf den ganzen Wahnsinn der an der Nutzung eines Webanlytic Tools à la Google, Matomo usw. dranhängt keine Lust mehr habe bin ich einfach auf GoAccess umgestiegen. Ist eine super Sache und für meine Zwecke völlig ausreichend, die Webserverlogs hat man ja zudem doch meistens eh. Netter Nebeneffekt, hat man vorher selber gehostet spart man sich sogar die Datenbank und die doch recht massiven Anfragen.
"GoAccess is an open source real-time web log analyzer and interactive viewer that runs in a terminal in *nix systems or through your browser."
MSSQL Export unter Ubuntu Linux
Juni 19, 2019 - Lesezeit: 5 Minuten
1. Installation der MSSQL Tools
Man benötigt dazu die MSSQL-Tools, welche nicht Teil der offiziellen Ubuntu Repositories sind, aber von Microsoft bereitgestellt werden. Folglich muss APT eine neue Quelle hinzugefügt werden.
curl https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -
curl https://packages.microsoft.com/config/ubuntu/16.04/prod.list | sudo tee /etc/apt/sources.list.d/msprod.listUpdate August 2022: Dieses Beispiel ist für einen Ubuntu Server 16, wer z.B. die 18.04/20.04/22 Version benutzt kann dies in der URL anpassen und 16.04 durch 18/20.04 ersetzten. MS supportert hier die aktuellen LTS Versionen.
Danach mit dem üblichen apt-get update die Quellen aktualisieren und die Tools sowie nötige ODBC Biblotheken installieren.
sudo apt-get update
sudo apt-get install mssql-tools unixodbc-devDie nötigen Programme finden sich danach unter
/opt/mssql-tools/bin
Dieser Pfad ist üblicherweise nicht in den Umgebungsvariablen der Shell enthalten, man muss die Tools also direkt ansprechen. Wer es bequemer mag fügt einfach den Pfad zu seinen Shell Umgebungsvariablen hinzu. Dazu kann man die .profile im Homeverzeichnis verwenden oder auch die .bashrc, sofern man die Bash Shell benutzt.
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrc
source ~/.bashrcDer erste Befehl ergänzt die zwei Programme unter /opt/mssql-tools/bin in der PATH Varibale ohne die bereits bestehenden Einträge zu überschreiben. Der source Befehl führt die aktualisierte Umgebung direkt aus.
Checken ob alles geklappt hat kann man einfach indem man sql in die Shell tippt, gefolgt von der Tab Taste, es sollte dann direkt sqlcmd vervollständigt werden, bzw. zur Auswahl stehen. Nachfolgende kann man eine einfache Abfrage an den MSSQL Server schicken, z.B.
sqlcmd -S localhost -d <datenbankname> -U sa -P <passwort> -Q "SELECT user_id FROM users"
Localhost wird vermutlich in den meisten Fällen durch die IP Adresse des MSSQL Servers ersetzt. Nachdem -d Argument lässt sich der Name der Datenbank angeben, natürlich ohne die Tag Klammern. Nachdem -Q Argument kommt einfach das gewünschte SQL Query in Anführungszeichen.
Ein Nachteil lässt sich direkt erkennen. Im Gegensatz zu z.B. MySQL/Maria DB muss nachdem Argument -P das Passwort im Klartext folgen und kann nicht einfach vor der Ausführung der Abfrage eingegeben werden. Aus Sicherheitsgründen sollte man daher am besten die entsprechenden sqlcmd Befehle aus der Bash History wieder entfernen und/oder die History für die Dauer der sqlcmd Befehle deaktiveren. Eine weitere Alternative wäre einen Benutzer auf dem MSSQL Server einzurichten der nur entsprechende Leserechte auf die benötigten Tabellen hat.
Die Bash History findet sich unter ~/.bash_history und lässt sich mit einem Editor (vi /nano) bearbeiten.
Deaktivieren kann man die History mit set +o history und wieder aktivieren mit set -o history. Vollständig leeren kann man die History übrigens auch mit history -c. Aber Achtung, bevor man die komplette History löscht, sollte man sich sicher sein das man darin keine Befehle hat, die man vielleicht noch wiederverwenden will und nicht auswendig kennt.
2. Export mit bcp
Neben sqlcmd wurde bcp (Bulk Copy Program) mit den MSSQL Tools installiert und damit lässt sich nun ein Export eines Datenbank Queries durchführen.
Folgender Befehl würde alle Inhalte der Tabelle Users aus der Datenbank Test_DB in die Datei user_export.txt exportieren.
bcp Users out user_export.txt -S localhost -U sa -P <passwort> -d Test_DB -c -t ','
Interessanter ist in meinen Augen aber nicht der Export einer ganzen Tabelle, sondern eines Querys. Dies geht wie folgt:
bcp "SELECT user_id, username FROM users" queryout users.txt -S localhost-U sa -P <-passwort> -d TEST_DB -c -t ','
Es werden zwei Felder aus der Tabelle users in die Datei users.txt exportiert und die Werte mit Komma getrennt.
Quellen:
https://docs.microsoft.com/de-de/sql/linux/sql-server-linux-setup-tools?view=sql-server-2017 https://docs.microsoft.com/de-de/sql/linux/sql-server-linux-migrate-bcp?view=sql-server-2017 https://docs.microsoft.com/de-de/sql/tools/bcp-utility?view=sql-server-2017
Linux Grundbefehle - Cheat Sheet
Oktober 3, 2018 - Lesezeit: ~1 Minute
Ein von mir erstelltes Cheat Sheet für ein Linux Grundlagen Seminar, findet sich unter folgendem Link:
https://www.cheatography.com/brice/cheat-sheets/linux-grundbefehle/